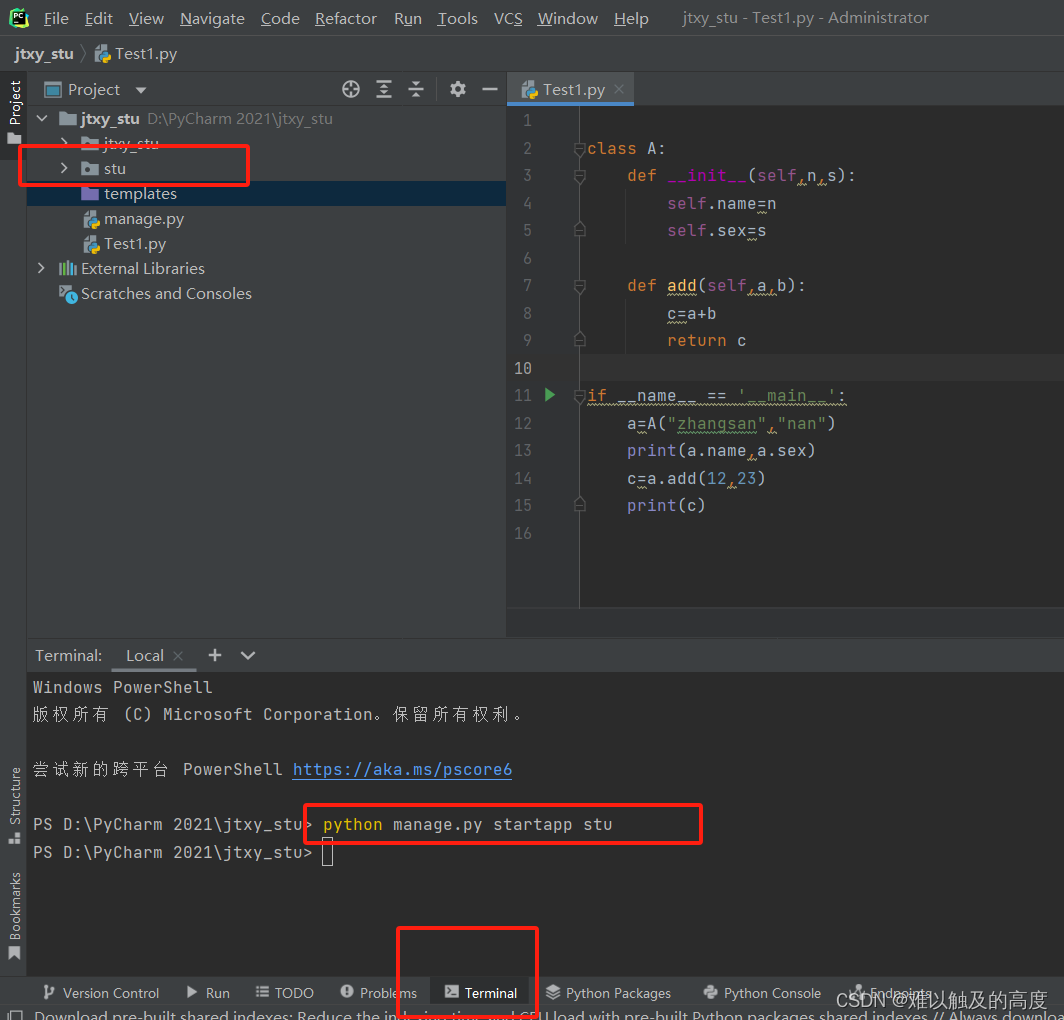
7.2RDD的操作方法
1.map(fac)映射转换
val rdd1 = sc.parallelize(List(1,2,3,4))
val result = rdd1.map(x => x + 2)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:25
result: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[1] at map at <console>:26
//转为数组对象
result.collect()
res1: Array[Int] = Array(3, 4, 5, 6)
// map()求平均值
val rdd1 = sc.parallelize(List(1,2,3,4))
val result = rdd1.map(x => x * x)
println(result.collect().mkString(";"))
1;4;9;16
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[2] at parallelize at <console>:29
result: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[3] at map at <console>:30
//键值对RDD
val wordsRDD = sc.parallelize(List("happy everyday","hello world","how are you"))
val PairRDD = wordsRDD.map(x => (x.split(" ")(0) , x))
PairRDD.collect()
wordsRDD: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[4] at parallelize at <console>:26
PairRDD: org.apache.spark.rdd.RDD[(String, String)] = MapPartitionsRDD[5] at map at <console>:27
res4: Array[(String, String)] = Array((happy,happy everyday), (hello,hello world), (how,how are you))
## *2.filter(func)过滤*
val rdd2 = sc.parallelize(List(1,2,3,4,5,6,7,8,9))
rdd2.filter(x => x > 4).collect()
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[6] at parallelize at <console>:25
res9: Array[Int] = Array(5, 6, 7, 8, 9)
// 学生数据
val students = sc.parallelize(List("daiblo java 100","hello scala 88","White python 89"))
//三元组
val studentsTup = students.map{x => val splits = x.split(" "); (splits(0),splits(1),splits(2).toInt)}
studentsTup.collect()
//成绩100
studentsTup.filter(_._3 == 100).map{x => (x._1 , x._2)}.collect().foreach(println)
(daiblo,java)
students: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[11] at parallelize at <console>:29
studentsTup: org.apache.spark.rdd.RDD[(String, String, Int)] = MapPartitionsRDD[12] at map at <console>:31
3.flatMap(func)映射
val rdd3 = sc.parallelize(List(1,2,3,4,5,6))
val rdd31 = rdd3.map(_ * 2)
rdd31.collect()
rdd3: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[19] at parallelize at <console>:28
rdd31: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[20] at map at <console>:29
res18: Array[Int] = Array(2, 4, 6, 8, 10, 12)
val rdd32 = rdd31.filter(x => x > 5).flatMap(x => x to 9)
rdd32.collect()
rdd32: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[22] at flatMap at <console>:28
res19: Array[Int] = Array(6, 7, 8, 9, 8, 9)
//切分单词
def tokenize(ws:String) = {ws.split(" ").toList}
val lines = sc.parallelize(List("coffee panda","happy panda","panda party"))
lines.map(tokenize).collect().foreach(println)
lines.flatMap(tokenize).collect().foreach(println)
List(coffee, panda)
List(happy, panda)
List(panda, party)
coffee
panda
happy
panda
panda
party
tokenize: (ws: String)List[String]
lines: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[31] at parallelize at <console>:30
4.distinct([numPartitions])去重转换
val rdd4 = sc.parallelize(List(1,2,3,4,4,2,8,8,4,6))
val distinctRdd = rdd4.distinct()
distinctRdd.collect()
rdd4: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[34] at parallelize at <console>:25
distinctRdd: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[37] at distinct at <console>:26
res30: Array[Int] = Array(4, 6, 8, 2, 1, 3)
5.union(otherDataset)合并转换
val rdd51 = sc.parallelize(List(1,3,4,5))
val rdd52 = sc.parallelize(List(2,3,4,7,8,9))
val result = rdd51.union(rdd52)
result.collect()
rdd51: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[38] at parallelize at <console>:27
rdd52: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[39] at parallelize at <console>:28
result: org.apache.spark.rdd.RDD[Int] = UnionRDD[40] at union at <console>:29
res31: Array[Int] = Array(1, 3, 4, 5, 2, 3, 4, 7, 8, 9)
6.intersection(otherRDD)交集且去重转换
val rdd61 = sc.parallelize(List(1,3,4,5))
val rdd62 = sc.parallelize(List(2,3,4,6,5,8,9))
val result = rdd61.intersection(rdd62)
result.collect()
rdd61: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[55] at parallelize at <console>:29
rdd62: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[56] at parallelize at <console>:30
result: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[62] at intersection at <console>:31
res37: Array[Int] = Array(4, 3, 5)
7.subtract(otherRDD)差集转换
val rdd71 = sc.parallelize(List(1,3,4,5))
val rdd72 = sc.parallelize(1 to 5).subtract(rdd71)
println(rdd72.collect().toBuffer)
ArrayBuffer(2)
rdd71: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[49] at parallelize at <console>:25
rdd72: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[54] at subtract at <console>:26
8.cartesian()笛卡尔积转换
val rdd81 = sc.parallelize(List(1,3,4,5))
val rdd82 = sc.parallelize(List(4,6,5))
val result = rdd81.cartesian(rdd82)
result.collect()
rdd81: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[63] at parallelize at <console>:27
rdd82: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[64] at parallelize at <console>:28
result: org.apache.spark.rdd.RDD[(Int, Int)] = CartesianRDD[65] at cartesian at <console>:29
res38: Array[(Int, Int)] = Array((1,4), (3,4), (1,6), (1,5), (3,6), (3,5), (4,4), (5,4), (4,6), (4,5), (5,6), (5,5))
9.mapValues()转换
val rdd91 = sc.parallelize(1 to 9 , 3)
rdd91.collect()
val result = rdd91.map(item => (item % 4 , item)).mapValues(v => v + 10)
println(result.collect().toBuffer)
ArrayBuffer((1,11), (2,12), (3,13), (0,14), (1,15), (2,16), (3,17), (0,18), (1,19))
rdd91: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[66] at parallelize at <console>:27
result: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[68] at mapValues at <console>:29
10.groupByKey()分组转换
val rdd101 = sc.parallelize(1 to 9 , 3)
val rddMap = rdd101.map(item => (item % 3 , item))
val rdd102 = rddMap.groupByKey()
rdd102.collect()
rdd101: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[69] at parallelize at <console>:25
rddMap: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[70] at map at <console>:26
rdd102: org.apache.spark.rdd.RDD[(Int, Iterable[Int])] = ShuffledRDD[71] at groupByKey at <console>:27
res40: Array[(Int, Iterable[Int])] = Array((0,CompactBuffer(3, 6, 9)), (1,CompactBuffer(1, 4, 7)), (2,CompactBuffer(2, 5, 8)))
11.reduceByKey(func,[numPartitions])分组聚合转换
val rddMap = sc.parallelize(1 to 12 , 4).map(item => (item % 4,item))
rddMap.collect()
rddMap: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[81] at map at <console>:27
res43: Array[(Int, Int)] = Array((1,1), (2,2), (3,3), (0,4), (1,5), (2,6), (3,7), (0,8), (1,9), (2,10), (3,11), (0,12))
val rdd111 = rddMap.reduceByKey((x,y) => x + y)
rdd111.collect()
rdd111: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[84] at reduceByKey at <console>:28
res45: Array[(Int, Int)] = Array((0,24), (1,15), (2,18), (3,21))
rddMap.reduceByKey((x,y) => x * y).collect()
res46: Array[(Int, Int)] = Array((0,384), (1,45), (2,120), (3,231))
12.combineByKey()分区聚合转换
val rdd121 = sc.parallelize(1 to 9 , 3)
val rdd122 = rdd121.map(item => (item % 3 , item)).mapValues(v => v.toDouble).combineByKey((v:Double) => (v,1),
(c: (Double,Int),v: Double) => (c._1 + v,c._2 + 1),
(c1: (Double,Int),c2: (Double,Int)) => (c1._1 + c2._1, c1._2 + c2._2))
rdd122.collect()
rdd121: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[86] at parallelize at <console>:25
rdd122: org.apache.spark.rdd.RDD[(Int, (Double, Int))] = ShuffledRDD[89] at combineByKey at <console>:26
res47: Array[(Int, (Double, Int))] = Array((0,(18.0,3)), (1,(12.0,3)), (2,(15.0,3)))
13.sortByKey(ascending,[numPartitions])
val rdd13 = sc.parallelize(List(("A",1),("B",3),("C",2),("D",5)))
val rdd131 = sc.parallelize(List(("B",1),("A",3),("C",2),("D",5)))
val rdd132 = rdd13.union(rdd131)
//按键聚合
val rdd133 = rdd132.reduceByKey(_ + _)
val rdd134 = rdd132.sortByKey(false)
rdd134.collect()
rdd13: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[90] at parallelize at <console>:25
rdd131: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[91] at parallelize at <console>:26
rdd132: org.apache.spark.rdd.RDD[(String, Int)] = UnionRDD[92] at union at <console>:27
rdd133: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[93] at reduceByKey at <console>:29
rdd134: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[96] at sortByKey at <console>:30
res48: Array[(String, Int)] = Array((D,5), (D,5), (C,2), (C,2), (B,3), (B,1), (A,1), (A,3))
14.sortBy(f:(T) => K, [ascending:Boolean = true],[numPartitions])转换
val goods = sc.parallelize(List("radio 23 30","soap 233 10","cup 12 20","bowl 35 8"))
goods: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[97] at parallelize at <console>:25
//按键排序
val goodsTup = goods.map{x => val splits = x.split(" "); (splits(0),splits(1).toDouble,splits(2).toInt)}
goodsTup.sortBy(_._1).collect().foreach(println)
(bowl,35.0,8)
(cup,12.0,20)
(radio,23.0,30)
(soap,233.0,10)
goodsTup: org.apache.spark.rdd.RDD[(String, Double, Int)] = MapPartitionsRDD[98] at map at <console>:26
//按值排序
//单价
goodsTup.sortBy(x => x._2 , false).collect().foreach(println)
(soap,233.0,10)
(bowl,35.0,8)
(radio,23.0,30)
(cup,12.0,20)
//数量
goodsTup.sortBy(_._3).collect().foreach(println)
(bowl,35.0,8)
(soap,233.0,10)
(cup,12.0,20)
(radio,23.0,30)
//数量与7的余数
goodsTup.sortBy(x => x._3 % 7).collect().foreach(println)
(bowl,35.0,8)
(radio,23.0,30)
(soap,233.0,10)
(cup,12.0,20)
//元组,按数组元素
goodsTup.sortBy(x => (-x._2 , -x._3)).collect().foreach(println)
(soap,233.0,10)
(bowl,35.0,8)
(radio,23.0,30)
(cup,12.0,20)
15.sample(withReplacement,fraction,seed)转换
val rdd15 = sc.parallelize(1 to 1000)
rdd15.sample(false,0.01,1).collect().foreach(x => print(x + " "))
110 137 196 231 283 456 483 513 605 618 634 784
rdd15: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[126] at parallelize at <console>:27
16.join(otherDataset,[numPartitions])转换
val rdd161 = sc.parallelize(List( ("scala" , 2) , ("java" , 3), ("python" ,4) ,("scala" , 8)))
val rdd162 = sc.parallelize(List( ("scala" , 2) , ("java" , 32), ("python" ,4) ,("hbase" , 8)))
val rdd163 = rdd161.join(rdd162)
rdd163.collect()
rdd161: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[128] at parallelize at <console>:25
rdd162: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[129] at parallelize at <console>:26
rdd163: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[132] at join at <console>:27
res57: Array[(String, (Int, Int))] = Array((scala,(2,2)), (scala,(8,2)), (python,(4,4)), (java,(3,32)))
val left_join = rdd161.leftOuterJoin(rdd162)
left_join.collect()
left_join: org.apache.spark.rdd.RDD[(String, (Int, Option[Int]))] = MapPartitionsRDD[138] at leftOuterJoin at <console>:29
res59: Array[(String, (Int, Option[Int]))] = Array((scala,(2,Some(2))), (scala,(8,Some(2))), (python,(4,Some(4))), (java,(3,Some(32))))
val full_join = rdd161.fullOuterJoin(rdd162)
full_join.collect()
full_join: org.apache.spark.rdd.RDD[(String, (Option[Int], Option[Int]))] = MapPartitionsRDD[141] at fullOuterJoin at <console>:27
res60: Array[(String, (Option[Int], Option[Int]))] = Array((scala,(Some(2),Some(2))), (scala,(Some(8),Some(2))), (python,(Some(4),Some(4))), (java,(Some(3),Some(32))), (hbase,(None,Some(8))))
17.zip()转换
val rdd171 = sc.parallelize(Array(1,2,3),3)
val rdd172 = sc.parallelize(Array("a","b","c"),3)
val ziprdd = rdd171.zip(rdd172)
ziprdd.collect()
rdd171: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[142] at parallelize at <console>:25
rdd172: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[143] at parallelize at <console>:26
ziprdd: org.apache.spark.rdd.RDD[(Int, String)] = ZippedPartitionsRDD2[144] at zip at <console>:27
res61: Array[(Int, String)] = Array((1,a), (2,b), (3,c))
18.转换操作keys与valuse
ziprdd.keys.collect
res63: Array[Int] = Array(1, 2, 3)
ziprdd.values.collect
res64: Array[String] = Array(a, b, c)
19.coalesce(numPartitions:Int)重新分区转换
val rdd = sc.parallelize(1 to 16 ,4)
rdd.partitions.size
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[149] at parallelize at <console>:27
res66: Int = 4
val coalrdd = rdd.coalesce(5)
coalrdd.partitions.size
coalrdd: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[150] at coalesce at <console>:26
res67: Int = 4
val coalrdd1 = rdd.coalesce(5,true)
coalrdd1.partitions.size
coalrdd1: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[154] at coalesce at <console>:26
res69: Int = 5
20.repartition(numPartitions:Int)重新分区转换
val rdd = sc.parallelize(1 to 16 ,8)
rdd.partitions.size
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[155] at parallelize at <console>:27
res70: Int = 8
val rerdd = rdd.repartition(2)
rerdd.partitions.size
rerdd: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[163] at repartition at <console>:28
res73: Int = 2
rerdd.getNumPartitions
res74: Int = 2
7.2.2行动操作
// 1.collect()
val rdd1 = sc.makeRDD(List(1,2,3,4,5,6,2,5,1))
rdd1.collect()
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[165] at makeRDD at <console>:28
res78: Array[Int] = Array(1, 2, 3, 4, 5, 6, 2, 5, 1)
//2.count()
println(rdd1.count())
9
//3.countByValue()
rdd1.countByValue()
res79: scala.collection.Map[Int,Long] = Map(5 -> 2, 1 -> 2, 6 -> 1, 2 -> 2, 3 -> 1, 4 -> 1)
//4.countByKey()
val rdd = sc.makeRDD(List( ("scala" , 2) , ("java" , 32), ("python" ,4) ,("hbase" , 8)))
rdd.countByKey()
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[169] at makeRDD at <console>:27
res80: scala.collection.Map[String,Long] = Map(scala -> 1, python -> 1, java -> 1, hbase -> 1)
// 5.first()
val rdd = sc.makeRDD(List("scala", "java" ,"python","hbase"))
rdd.first()
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[172] at makeRDD at <console>:28
res81: String = scala

![[qnx] 通过zcu104 SD卡更新qnx镜像的步骤](https://img-blog.csdnimg.cn/direct/c7eb82c8f7d84fc0ae73e83b0dee9ac0.png)